画像の生成AI
Stable Diffusionの仕組み・間取り図の画像生成
Jiyan Schneider
Agenda
- Latent/Stable Diffusion とは
- Latent Diffusion のパーツ
- パーツの合わせ方 (画像の生成の仕方)
Latent/Stable Diffusion とは
- Latent Diffusion は画像生成 の手法
- Stable Diffusion は latent diffusion ベースの stability AI のオープンソースモデル
- 最も基本的な使い方は プロンプトを入れれば、画像をアウトプットしてくれる
- https://stability.ai/stable-assistant
Latent diffusion のアウトプット

Figure 1: “An astronaut riding a horse” (軽いモデルを使って生成した画像)
Latent diffusion のパーツ
- U-NET
- VAE
- Conditioning Model (Clip)
U-NET
- 元々は生物医学的画像セグメンテーション用に設計された
- 最も大事なことが学習問題の設定
- Diffusion 系のモデルでは、基本的に画像のノイズを予測するようになっている
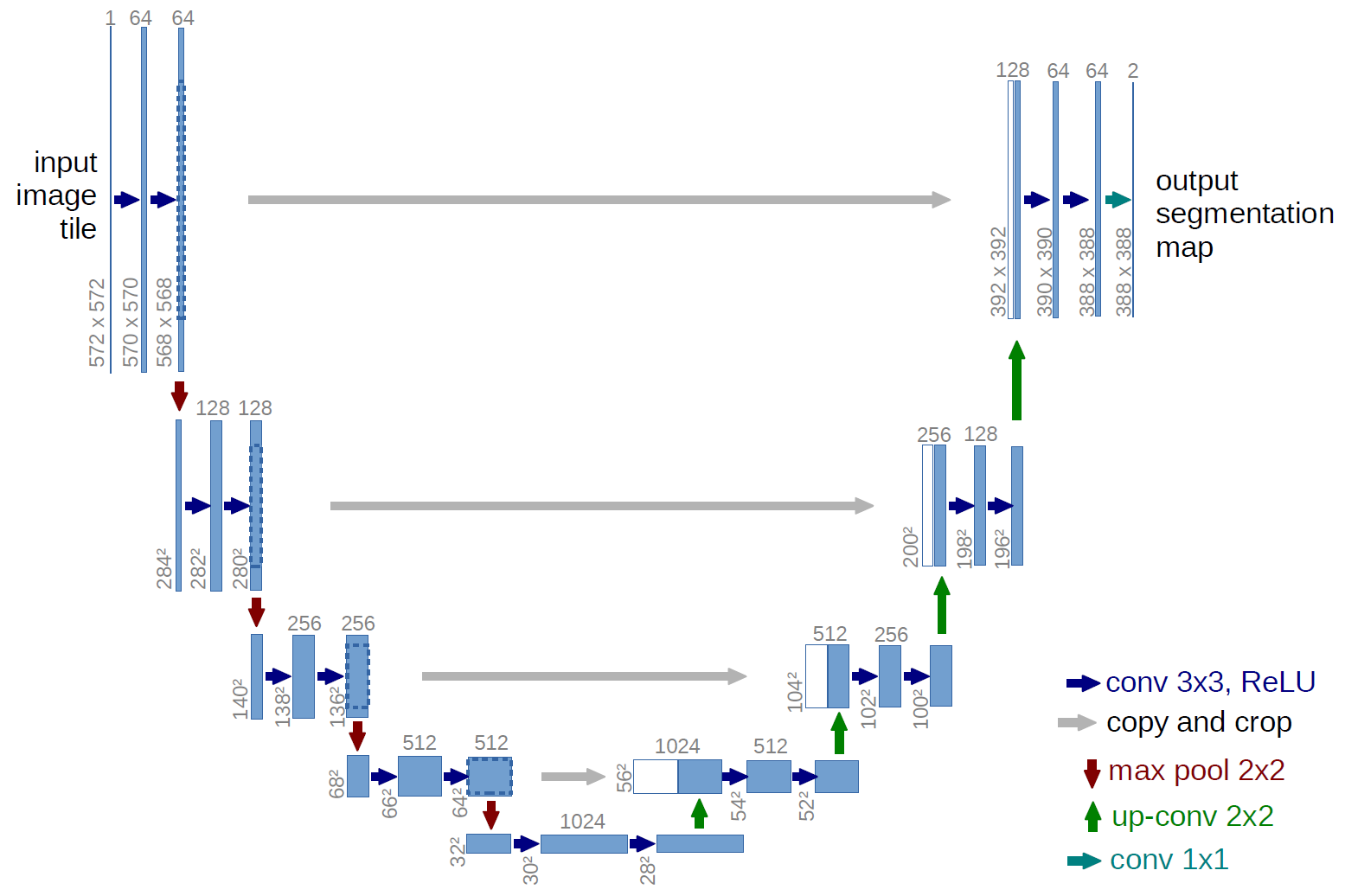
Figure 2: U-net のアーキテクチャーのイメージ(Ronneberger, Fischer, and Brox 2015)
U-net の入出力
Diffusion 系のモデルは基本的に
- インプット
- ノイズを加えた画像
- その画像を説明する文章、とかタグとか(任意)
- アウトプット
- ノイズはどこにあるか
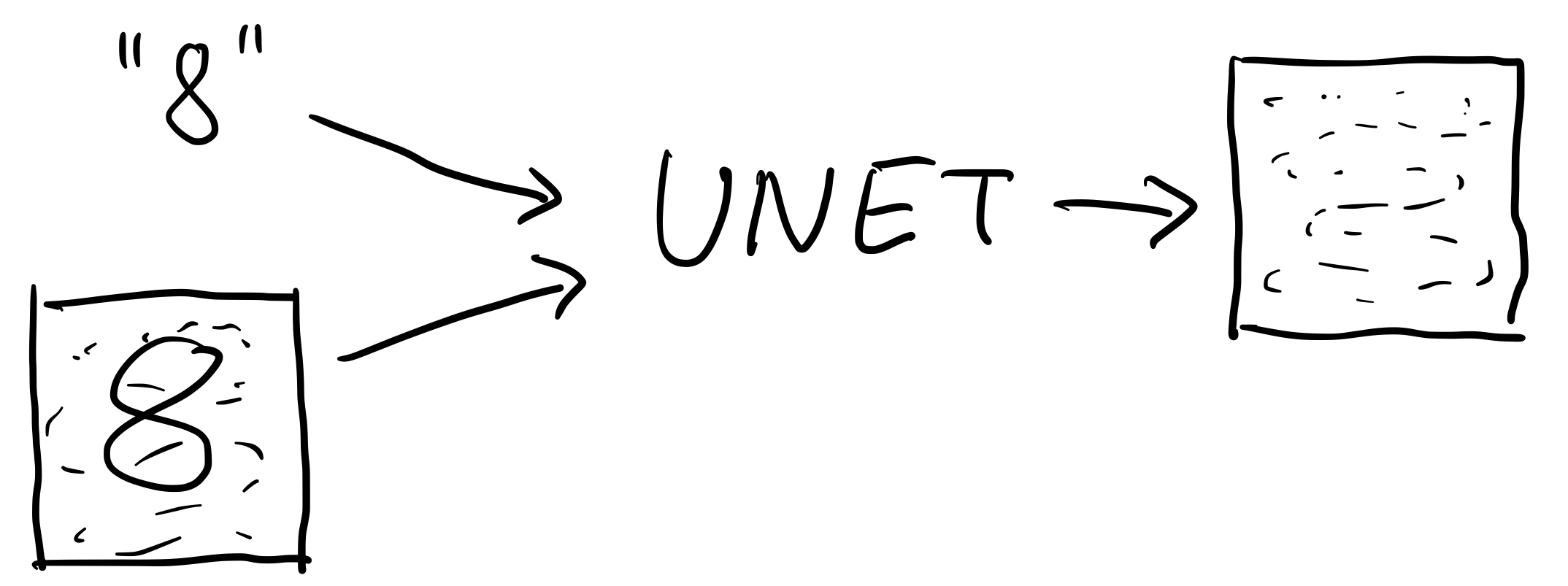
Figure 3: U-net のニューラルネットワークは Noisy な画像のノイズを予測している
ノイズの画像
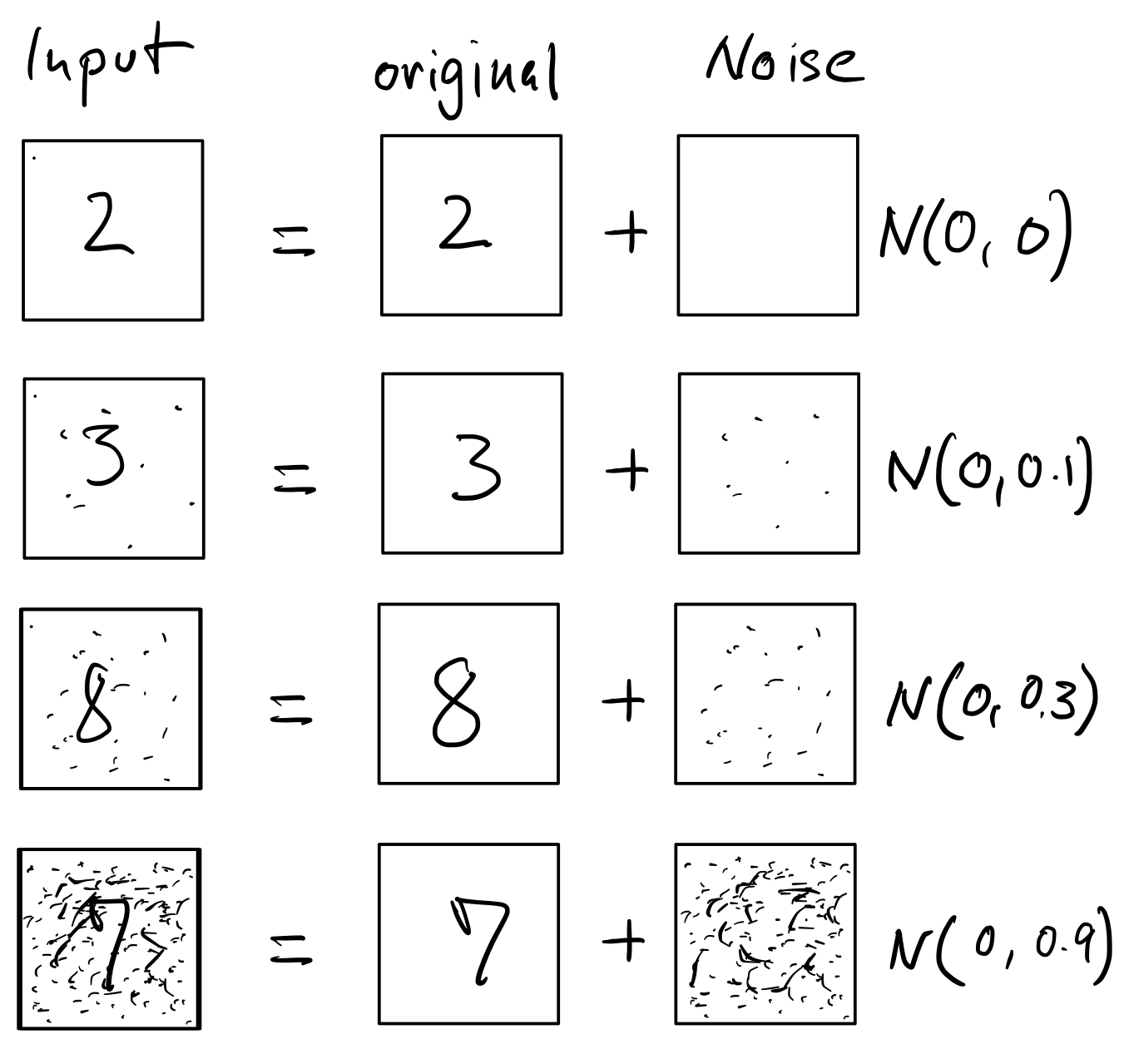
Figure 4: U-net のインプットは、画像さえ持ってれば簡単に作れる
Variational Auto-Encoder (VAE)
- 2014 にできた NN の種類
- Web のDemoが非常に面白い
- 画像の圧縮と再構築を行うニューラルネットワーク
- 入力画像を圧縮し、そこから元の画像を再生成
- インプットとアウトプットの MSE で評価
- 単純にインプットを復元するための NN
- Latent Diffusion では基本的に畳み込みの層を使う
- 圧縮された画像を “Latent” と呼ぶ
VAE の構造

Figure 5: VAE の構造
- エンコーダー:画像を Latent Representation(潜在表現?)に変換
- デコーダー:Latents から画像を再構築
- 画像の本質的特徴を圧縮して表現
- 類似した特徴を持つ画像は近い位置に配置される
Conditioning Model
- インプット:テキスト
- アウトプット:テキストの Embedding
- 通常、LLM に基づいている
- Latent diffusion では CLIP を使っている
- Conditioning model のアウトプット空間にすごく興味がある

使い方
- 三つのパーツを合わせるとこうなる
- インプットの画像が x、VAE の Encoder のアウトプットが Latents z
- これが Latent diffusion の 貢献
- ノイズを加えた画像 z_T
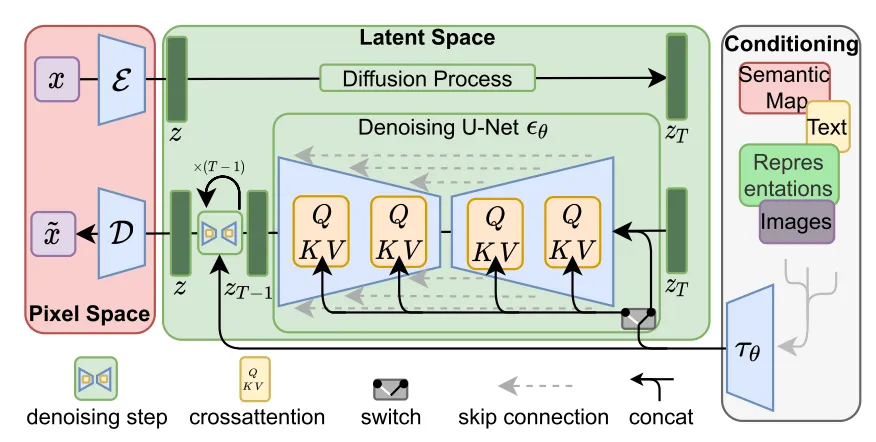
Figure 6: Latent Diffusion の全体図 (Rombach et al. 2022)
新しい画像の生成
- ランダムノイズの Latents を生成
- テキストプロンプトを入力
- Conditioning Model で 文章の Embedding を出力
- U-Net、とテキスト Embedding で Latents のノイズを予測し、Latent から差し引く
- 4 をしばらく繰り返す
- VAE がデノイズされた潜在表現を画像に変換

Figure 7: プロンプト:Happy sea turtle on beach in the style of Paul Signac
他の画像をベースに生成
もちろんノイズだけじゃなくても、sketch とかをベースにして作成する こともできる

Figure 8: Before: My masterful turtle at the beach sketch
他の画像をベースに生成

Figure 9: After: “Turtle chilling at the beach in the style of Keith Haring”.
Bibliography
Rombach, Robin, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. “High-Resolution Image Synthesis with Latent Diffusion Models.” arXiv.
Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. 2015. “U-Net: Convolutional Networks for Biomedical Image Segmentation.” arXiv.